In today’s post I want to explore the rigid body motion.
When a body moves, we can divide it into two distinct types of motion, a translation and a rotation. The translation can be treated with Newton’s Laws applied to the Center of Mass, but the rotation is a topic that often eludes people.
To try to develop the theory for the rotation of bodies we have to review the concept of a point mass particle, a body with negligible dimension, which means that rotation is undefined. How can we see if a point rotates? This means that rotation is a characteristic of sets of point particles and not of individual particles. This is the way we are going to define a rigid body of non-negligible dimensions, as a set of point particles whose distances between one another is constant.
Now that we know what we are studying, let’s define correctly the center of mass, a concept very important (and handy) for the study of rotations. The center mass corresponds to the position of the body (interior to the body or not) such that if the intire mass was compressed into that point, its motion could be accounted by only our knowledge so far of Newton’s equation. Imagine you throw a stick in the air with some rotation, there will be a point in the which will describe a parabola as predicted by the equations of a throw. The remaining points can be thought of translating with the center of mass (CM) and rotating around it.
The position of the center of mass can be calculated by:
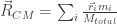
i corresponds to a point particle of the body and we are summing over all of them.
As I said before the motion of each particle can be understood as a translation with the CM as well as a rotation around it. This means that the displacement in a particle i is given by:

Where 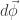
Now let’s try to find more about rotations by writing the energy of the system, which will be the sum of the kinetic energies of all particles (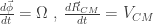
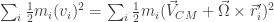
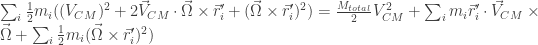
However since 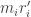
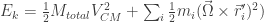
The energy then reinforces the idea that the motion is a translation of the CM plus a rotation around the CM.
Now let’s see if by expanding the energy of rotation we can find fundamental structure.
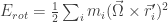
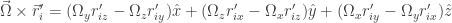
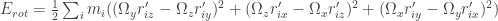
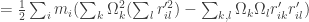
This last summation part needs care, if you don’t see it at first, please read it carefully. Dropping the summation sign to make the notation less cumbersome we have:
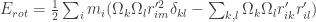
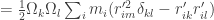
We know define a new quantity, the tensor of inertia 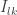
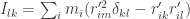
Then the rotation energy can be written simply as:
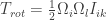
And 
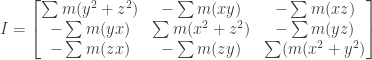
If the body is continuous we just transform the summations into integrals over the entire volume of the body.
So now the inertial moment of a body is not only a scalar, it actually depends on the various directions of the rotation.
However the is a cool result which states that it is always possible to find a set of directions such that
The next point in our analysis will be developing an analog to the linear momentum for rotations, and then develop a analog to the Newton’s second equation but for rotations.
In the generalization of the momentum, we start by defining it as $m\vec r\times \vec v$ for a point particle. Then for a full body:
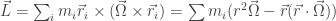
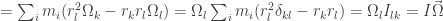
Deriving 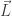
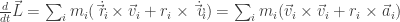
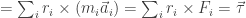
Now we found a quatity that varies our Angular momentum the same way as in Newton’s second law.
We now have the basis for the rigid body motion.
References: Landau Volume 1 Mechanics
 and
and  . There is a general rule, called Leibniz’s rule, which gives a slightly easier way of computing it, without the process of calculating every step. The rule states that
. There is a general rule, called Leibniz’s rule, which gives a slightly easier way of computing it, without the process of calculating every step. The rule states that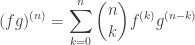 .
. and
and  ,
,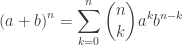 .
. . We will still need to calculate the first 5 derivatives of both functions, but that is pretty straight forward. We also calculate the 5th line of Pascal’s triangle.
. We will still need to calculate the first 5 derivatives of both functions, but that is pretty straight forward. We also calculate the 5th line of Pascal’s triangle.
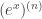
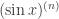

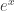
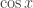



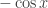
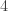

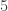
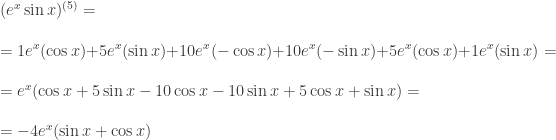 .
. . The operation
. The operation  is such that:
is such that:
 and F is multiplying by
and F is multiplying by  :
:
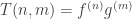 and F is the derivative operator:
and F is the derivative operator: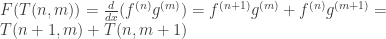
 stands for standard addition. We must also state the initial condition,
stands for standard addition. We must also state the initial condition,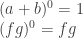
 is a vector space and
is a vector space and 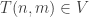 for every non-negative m,n;
for every non-negative m,n;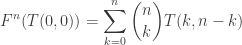 .
.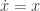 which gives rise to the exponential function.
which gives rise to the exponential function.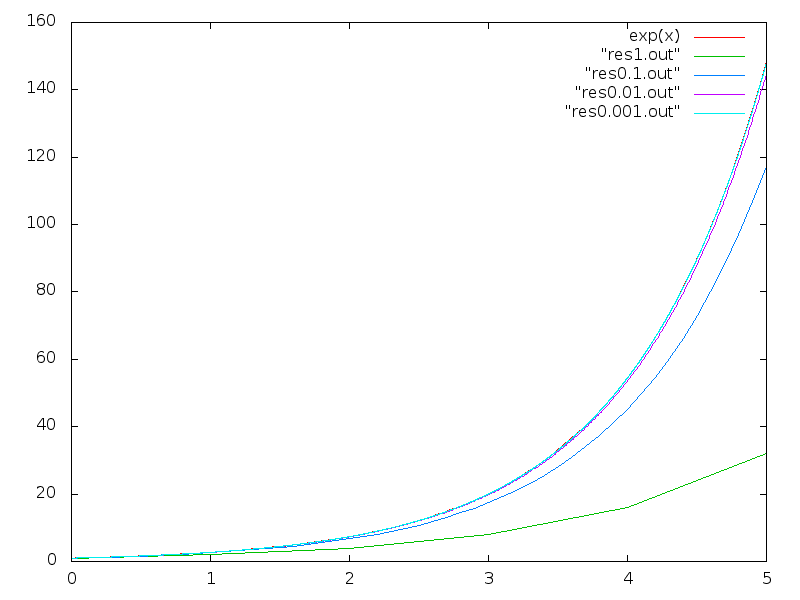
 to calculate the next step, to a point
to calculate the next step, to a point  why is there an error?
why is there an error?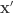 to calculate
to calculate 
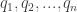 and maybe time such that we have their derivatives as a function of these variables:
and maybe time such that we have their derivatives as a function of these variables: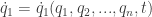
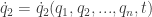
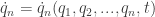
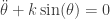 – The system of a simple pendulum
– The system of a simple pendulum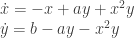 – Biological processes like glycolisis
– Biological processes like glycolisis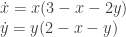 – Growth models of species
– Growth models of species